
티스토리 뷰
지난 시간에 학습후 경량화에 해당하는 Post Training Quanitzation 에 대해서 진행해보았는데요. 오늘은 학습 과정에서 Quantization을 가정하고 시뮬레이션을 같이 돌림으로서 정확도를 더 높이면서 경량화 할 수 있는 방법에 대해서 알아보도록 하겠습니다.
- Post Training(PTQ, static) : 학습 이후에 quantization 하는것
- Quantization Aware Training(QAT) : 학습 과정에서 quantization을 가정하고 시뮬레이션을 같이 돌림
아무래도 학습 하면서 경량화 하는 방법을 적용하고 나서 학습 후 경량화를 한 번 더 적용하는게 경량화적으로 이점이 있을 거라 생각하면서 혹시나 학습 후 양자화 내용을 확인하지 못하신 분은 아래 링크를 빠르게 훓어보고 오도록 하겠습니다.
https://hero-space.tistory.com/147
[AI 모델 경량화] EfficientNet 학습 후 양자화 with TFLite
지난 시간에 양자화가 무엇이고 Tensorflow 프레임워크 내에 있는 TFLite를 이용해서 양자화가 가능한 방법에 대해서 설명했었는데요. https://hero-space.tistory.com/146 AI 모델 경량화의 지름길 TFLite Quantiza
hero-space.tistory.com
기대목표
- 모델의 사이즈는 4배 이상 줄어들 것이다.
- 일반적으로 1.5배에서 4배에 달하는 CPU 레이턴시 향상이 있을 것이다.
API 호환성
- Quantization Aware Training은 아래 조건이 충족되어야만 진행할 수 있습니다. (Quantization Aware Training은 현재 실험적이며(Nightly), 역호환성(Backward Compatibility)는 고려되지 않는다.)
- Model Building
- tf.keras 에만 적용될 수 있으며, Sequential Model과 Functional Model에만 적용 가능
- Tensorflow 버전
- TF 2.x 버전만 호환 가능
- TF 2.x 버전의 tf.compat.v1은 지원되지 않음
- TF 2.x 버전만 호환 가능
- Tensorflow 실행 모드
- eager execution (즉시 실행 모드)
- Model Building
지원 목록
지원되는 목록은 아래와 같습니다.
- Model Coverage
- whitelisted 레이어를 사용하는 모델
- Conv2D와 DepthwiseConv2D 레이어를 사용하는 BatchNormalization
- 아주 예외적인 몇몇 케이스에 Concat을 지원
- 하드웨어 가속
- EdgeTPU
- NNAPI
- TFLite Backend
- 양자화된 상태로 출하
- ONLY 합성곱 레이어 axis당 양자화만 출하 가능
- tensor당 양자화는 출하 불가능
Tensorflow Official Result
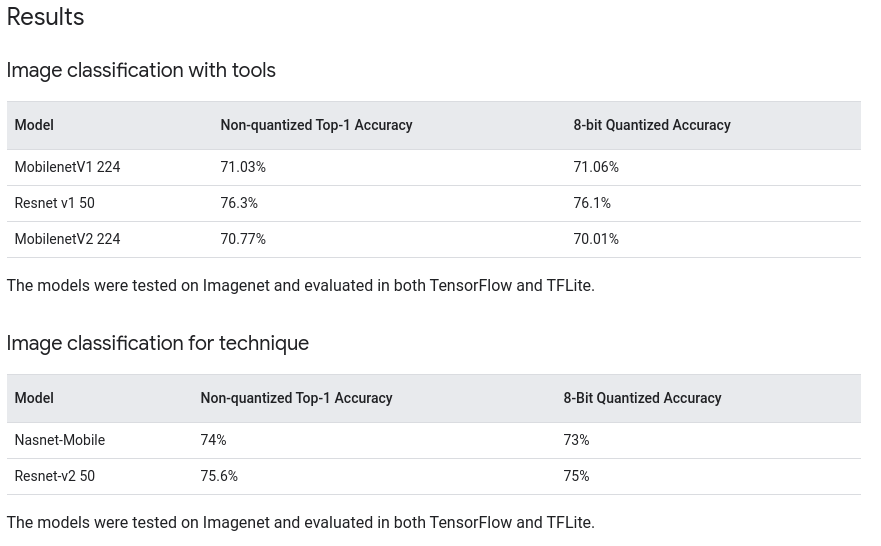
Comprehensive Guide
Setup
- 기존 tensorflow 패키지는 uninstall 하고, tf-nightly를 다운로드 받아야 한다.
# Terminal
$ pip uninstall -y tensorflow
$ pip install tf-nightly
$ pip install tensorflow-model-optimization- Library import는 아래와 같이 한다.
import tempfile
import os
import tensorflow as tf
import tensorflow_model_optimization as tfmotProgress
- Quantization 없이 모델 학습 진행
예시) MNIST 학습 모델
# Load MNIST dataset
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Normalize the input image so that each pixel value is between 0 to 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
# Define the model architecture.
model = keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(28, 28)),
tf.keras.layers.Reshape(target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
# Train the digit classification model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_images,
train_labels,
epochs=1,
validation_split=0.1,
)위 예시에서 알 수 있듯, 모델 컴파일은 하지 않은 채, fit까지만 진행합니다.
- Pre-trained 모델을 불러와서 Quantization Aware Training으로 양자화 및 컴파일 진행
quantize_model = tfmot.quantization.keras.quantize_model
# q_aware stands for for quantization aware.
q_aware_model = quantize_model(model)
# `quantize_model` requires a recompile.
q_aware_model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
q_aware_model.summary()
train_images_subset = train_images[0:1000] # out of 60000
train_labels_subset = train_labels[0:1000]
q_aware_model.fit(train_images_subset, train_labels_subset,
batch_size=500, epochs=1, validation_split=0.1)- 즉, 일단 원래 모델로 학습을 완료 후, Quantization Aware Training 기법으로 Pre-trained 된 모델을 복사하여 다시 컴파일, 그리고 다시 학습시켜야 합니다. (학습 시간은 2배로 들어간다.)
- 모델 Evaluation
_, baseline_model_accuracy = model.evaluate(
test_images, test_labels, verbose=0)
_, q_aware_model_accuracy = q_aware_model.evaluate(
test_images, test_labels, verbose=0)
print('Baseline test accuracy:', baseline_model_accuracy)
print('Quant test accuracy:', q_aware_model_accuracy)- 결과

이후에는 TFLite로 변환하여 Post-training Quantization 진행하면 됩니다. 텐서플로우 라이트로 여러분들의 모델 파일들을 쉽게 줄여지셨나요? 다음 시간엔 PTQ에서 UINT8로 경량화하는 방법에 대해서 공유하도록 하겠습니다.
'Technology > AI, ML, Data' 카테고리의 다른 글
| 박스플롯(Box plot) 파이썬으로 구현하기 (0) | 2023.03.16 |
|---|---|
| 박스플롯(Box plot) 데이터 분석 (0) | 2023.03.15 |
| [AI 모델 경량화] Representative Dataset 이용한 UINT8 양자화 (0) | 2023.02.06 |
| [AI 모델 경량화] EfficientNet 학습 후 양자화 with TFLite (1) | 2023.02.02 |
| [AI 모델 경량화] AI 모델 경량화의 지름길 TFLite Quantization (0) | 2023.01.31 |
댓글