
티스토리 뷰
회귀 분석에 대한 간단한 설명을 지난 시간에 진행했었는데요. 오늘은 실제 파이썬으로 구현하는 과정을 설명드리도록 하겠습니다. 회귀분석이 기억나지 않으시는 분은 잠시 아래 글을 읽고 오실게요!
2023.03.17 - [Technology/AI, ML, Data] - 회귀분석(Regression Analysis)
회귀분석(Regression Analysis)
지난 시간에 박스플롯을 이용해서 데이터의 분포를 시각화 해봤었는데요, 오늘은 회기분석의 정의에 대해서 설명해보도록 하겠습니다. 제 블로그는 단순한 설명에 그치지 않고 실제 구현까지
hero-space.tistory.com
데이터
데이터는 이전에 박스플롯에서 썼던 데이터와 동일합니다. 박스플로의 경우 개별적인 요인에 대한 데이터의 유효성을 검증하는 것이었으나, 어떤 범위에 있다라는 것이기 때문에 특정 범위를 벗어나는 값에 대한 아웃라이어 측면에서 유의미했고, 제가 원하는 데이터 분석결과는 아니었습니다.
앞서도 한번 설명 드렸지만, 데이터 분석이라는 것은 크게 2가지의 목적이 있다고 생각되어지는데요,
- 많은 양의 데이터를 분석하기 위함
- 데이터 간의 연관성이나 인사이트를 얻기 위함
위와 같기 때문에 적은 데이터의 경우는 엑셀의 피봇데이블을 돌려도 충분히 알 수 있습니다. 따라서 어떤 데이터를 가공해서 분석하는 것은 그만큼 불필요한 일로 보일수 있지만 데이터는 쌓을 수록 그 분석이 명확해지고 신뢰도가 올라가기때문에 그러한 수준의 데이터를 엑셀이나 손으로 분석하는 것은 한계점을 느낄 수가 있겠지요.
데이터 핵심항목
- 잠자러 간 시각
- 전체 수면 시간(잠자러 들어간 시간 ~ 일어나서 잠자리에서 나온 시간) - 분으로 환산
- 실제 수면 시간(잠자러 들어간 시간 - 실제 잠들때 까지 걸린사간) ~ 일어난 시간) - 분으로 환산
- 일어난 시각
- 중간에 깬 횟수
- 중간에 깬 이유
- 수면의 질 주관 점수
다시한번 데이터 분석할 요인들을 정리하면 위와 같습니다. 이 중에서 실제 수면시간과 수면의 질 주관 점수를 X, Y축에 두고 어떤 결과가 나오는지 구현을 해보도록 하겠습니다.
구현
def simple_linear_regression(log, org_data, criteria, without_outliers=False):
log.info("Simple Linear Regression Start.")
font_files = font_manager.findSystemFonts(
fontpaths='./data/font', fontext="ttf")
for font_file in font_files:
font_manager.fontManager.addfont(font_file)
font_name = font_manager.FontProperties(fname=font_files[0]).get_name()
plt.rc('font', family=font_name)
plt.rc('axes', unicode_minus=False)
linear_regression = LinearRegression()
data = deepcopy(org_data)
avg_coef = 0
users = []
for user in data.index:
if user not in users:
users.append(user)
else:
continue
item_1 = REALSLEEPTIME_MM
item_2 = SLEEPQUALITY
log.info("Current Criteria: <" + item_1 + " | " + item_2 + ">")
x = data[item_1][user].values.reshape(-1, 1)
y = data[item_2][user].values.reshape(-1, 1)
sns.set(rc={'figure.figsize': (30, 10)})
plt.rc('font', family=font_name)
plt.rc('axes', unicode_minus=False)
linear_regression.fit(x, y)
print(str(user)+": "+"y = {} x + {}".format(
linear_regression.coef_[0], linear_regression.intercept_))
avg_coef += linear_regression.coef_[0][0]
curr_at = 'simple_linear_regression_plus'
username = user
output_filename = username+'/'+curr_at+'/'+'random_' + \
item_1+'-'+item_2+'_regression'+'_simple_linear_plus'
# check for directory
if not os.path.isdir(os.getcwd()+'/output/'+username):
os.mkdir(os.getcwd()+'/output/'+username)
if not os.path.isdir(os.getcwd()+'/output/'+username+'/'+curr_at):
os.mkdir(os.getcwd()+'/output/'+username+'/'+curr_at)
b0 = linear_regression.intercept_
b1 = linear_regression.coef_[0]
x_minmax = np.array([min(x), max(x)])
y_fit = x_minmax * b1 + b0
sns.lmplot(x=item_1,
y=item_2,
data=data.query("index == " + "'" + str(user) + "'"),
line_kws={'color': 'red'},
scatter_kws={'edgecolor': "white"},
x_jitter=0.9,
robust=without_outliers,
palette='coolwarm',
height=20,
aspect=60/20)
plt.title(username+": "+"y = {} x + {}".format(b1, b0))
plt.xlabel(item_1)
plt.ylabel(item_2)
plt.xticks(rotation=45)
plt.savefig(os.getcwd()+'/output/'+output_filename+'.png')
plt.clf()
avg_coef /= len(users)
print("AVG_COEFFICIENT:", avg_coef)
# All Users
item_1 = REALSLEEPTIME_MM
item_2 = SLEEPQUALITY
log.info("Current Criteria: <" + item_1 + " | " + item_2 + ">")
x = data[item_1].values.reshape(-1, 1)
y = data[item_2].values.reshape(-1, 1)
sns.set(rc={'figure.figsize': (20, 10)})
plt.rc('font', family=font_name)
plt.rc('axes', unicode_minus=False)
linear_regression.fit(x, y)
print(str(user)+": " +
"y = {} x + {}".format(linear_regression.coef_[0], linear_regression.intercept_))
curr_at = 'simple_linear_regression_plus'
username = 'All'
output_filename = username+'/'+curr_at+'/'+'random_' + \
item_1+'-'+item_2+'_regression'+'_simple_linear_plus'
# check for directory
if not os.path.isdir(os.getcwd()+'/output/'+username):
os.mkdir(os.getcwd()+'/output/'+username)
if not os.path.isdir(os.getcwd()+'/output/'+username+'/'+curr_at):
os.mkdir(os.getcwd()+'/output/'+username+'/'+curr_at)
b0 = linear_regression.intercept_
b1 = linear_regression.coef_[0]
x_minmax = np.array([min(x), max(x)])
y_fit = x_minmax * b1 + b0
sns.lmplot(x=item_1,
y=item_2,
data=data,
line_kws={'color': 'red'},
scatter_kws={'edgecolor': "white"},
x_jitter=0.9,
robust=without_outliers,
palette='coolwarm')
plt.title(username+": "+"y = {} x + {}".format(b1, b0))
plt.xlabel(item_1)
plt.ylabel(item_2)
plt.xticks(rotation=45)
plt.savefig(os.getcwd()+'/output/'+output_filename+'.png')
plt.clf()
relationship_sleep = data.copy()[[item_1, item_2]]
relationship_sleep.to_csv(os.getcwd()+'/output/'+output_filename+'.csv')
return싸이킷런 패키지에서 Linear_regression을 이용한 을 제외하고는 그래프를 그려 이미지로 저장하고 Raw 데이터를 csv로 마지막에 뽑아내고 있습니다. 결과를 한번 보면 아래와 같습니다. 실제 수면시간(분)이 커질수록 수면의 질이 높다는 관계가 양수의 기울기를 나타내고 있습니다. 물론 일부 그렇지 않은 인원들도 있지만 전체 모수에서 분석을 했기에 대체적이런 데이터 분석이 나올 수가 있었고 두 요인은 상당히 높은 관계가 있음이 확인되었습니다.
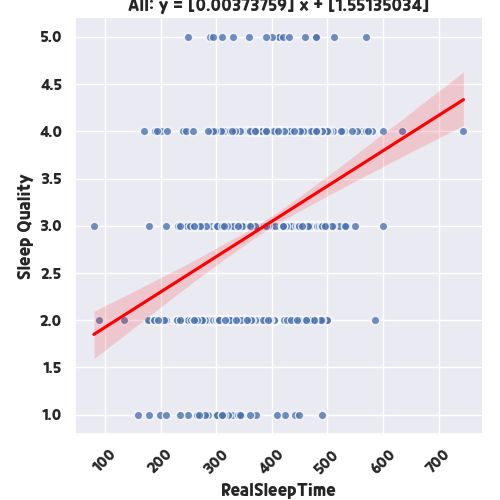
그러면 수면 주관점수와, 잠들기까지 걸린 시간을 비교해볼까요? 코드 상에서 Item1에 대한 요인만 바꿔서 다시한번 돌려보도록 하겟습니다.
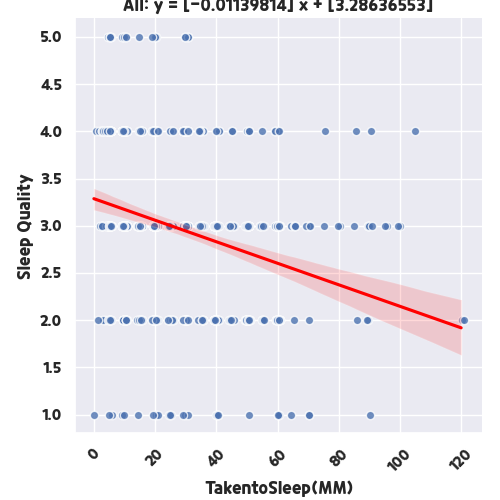
잠들기까지 걸린 시간이 적을 수록 수면의 질이 높다는 데이터 분석결과가 나왔습니다. 상식적인 수준에서의 결과일지라도 이렇게, 데이터 분석은 데이터 통계 또는 머신러닝 자체를 이용하는 것보다는
- 분석이 될 수 있도록 데이터 가공해주고
- 시각화하기 위해 그래프를 그려주며
- 인사이트를 뽑아내는 과정
이렇게 정의할 수 있습니다. 지난번 박스플롯에 비해서 어떠한가요? 요인별로 연관성이 보이니, 이제 조금 다음 스텝으로 갈 수 있을 것 같은데요. 이렇게 단위 적인 분석 방법은 꽤 많고 새로운 것들도 많으며, 진화하고 있기 때문에 최신동향과 기술을 잘 확인해보는 습관이 중요할 것 같습니다. 위에서 코드 설명을 조금더 상세하게 하지 않은 건 아직 저 코드만으로 직접 자신이 가진 데이터를 분석하는것은 사실은 어렵습니다. 먼저 데이터 분석으로 통해 무엇을 하려고 하는지, 어떤 플로우를 가지고 분석을 해야하는지 감을 잡으실 수 있도록 내용을 공유해드리는 것이구요. 그럼 다음 데이터 분석시간에 뵙겠습니다.!
'Technology > AI, ML, Data' 카테고리의 다른 글
| 회귀분석(Regression Analysis) (0) | 2023.03.17 |
|---|---|
| 박스플롯(Box plot) 파이썬으로 구현하기 (0) | 2023.03.16 |
| 박스플롯(Box plot) 데이터 분석 (0) | 2023.03.15 |
| [AI 모델 경량화] Representative Dataset 이용한 UINT8 양자화 (0) | 2023.02.06 |
| [AI 모델 경량화] Quantization Aware Training 으로 경량화 하기 (1) | 2023.02.05 |